PyTorch internals
此为原创文章,转载请务必保留出处
译者序:这篇博文是一篇非常新的介绍PyTorch内部机制的文章,作者Edward Z Yang来自于Stanford大学,是PyTorch的核心开发者之一。文章中介绍了如何阅读PyTorch源码和扩展PyTorch的技巧。目前讲PyTorch底层的文章不多,故将其翻译出来,才疏学浅,如有疏漏,欢迎留言讨论。
原文链接:http://blog.ezyang.com/2019/05/pytorch-internals/
翻译努力追求通俗、易懂,有些熟知的名词没有进行翻译比如(Tensor, 张量) 部分专有名词翻译对照表如下
英文 译文 autograde 自动微分 tensor 张量(翻译保持了tensor) layout 布局(主要讲的是数据在内存中的分布) device 设备(比如CPU或者GPU) dtype 数据类型(比如 float, int) kernels 实现某个操作的具体代码(翻译保持了kernels) operation 操作(比如加,矩阵相乘) operator 操作符 metadata 元数据 stride 步长 dimension 维度 view 视图 offset 偏移量 storage 存储 dispatch 分派 wrap 封装 unwrap 解封装(翻译保持了unwrap)
这篇博文是一篇长论文形式的关于PyTorch内部机制的演讲材料,我于2019年5月14日在PyTorch纽约见面会中进行了这场演讲。
Intros

大家好!我今天带来的是关于PyTorch内部机制的演讲

这个演讲的受众是那些已经用过PyTorch,问过自己”如果我能给PyTorch做些贡献岂不美哉”但是又被PyTorch庞大的C++代码吓退的人。实话说:有时候PyTorch的代码库确实又多又杂。这个演讲的目的是给你提供一张导向图:告诉你PyTorch这个”支持自动微分的tensor库”的基本结构,给你介绍一些能够帮助你在PyTorch代码库中畅游的工具和小技巧。我假设你之前写过一些PyTorch代码,但是不需要你对如何实现一个机器学习库有过深入的理解。

这个演讲分为两个部分:在第一部分,我将会向你介绍tensor库的基本概念。我将会从你所熟知的tensor数据类型谈起,并且详细讨论这个数据类型提供了什么,作为帮助你理解它是如何实现的指引。如果你是一个PyTorch的重度用户,大部分内容都是你所熟知的。我们也将会讨论扩展PyTorch的”三要素”:布局(layout),设备(device)和数据类型(dtype),这三个要素指导着我们选择哪种方式扩展Tensor类。在纽约的现场演讲中,我跳过了关于自动微分(autograde)的部分,不过我在这个博文中简要得讨论了它们。
第二部分包含了PyTorch源码的细节。我会告诉你如何在复杂autograd的代码中找到逻辑,哪些代码是重要的,哪些代码是老旧的,以及所有PyTorch提供的易用工具来帮助你编写kernels。
Concepts
Tensor/Storage/Strides
Tensor 是PyTorch的核心数据结构。你可能对tensor的概念已经相当了解了:它是包含若干个标量(标量可以是各种数据类型如浮点型、整形等)的n-维的数据结构。我们可以认为tensor包含了数据和元数据(metadata),元数据用来描述tensor的大小、其包含内部数据的类型、存储的位置(CPU内存或是CUDA显存?)
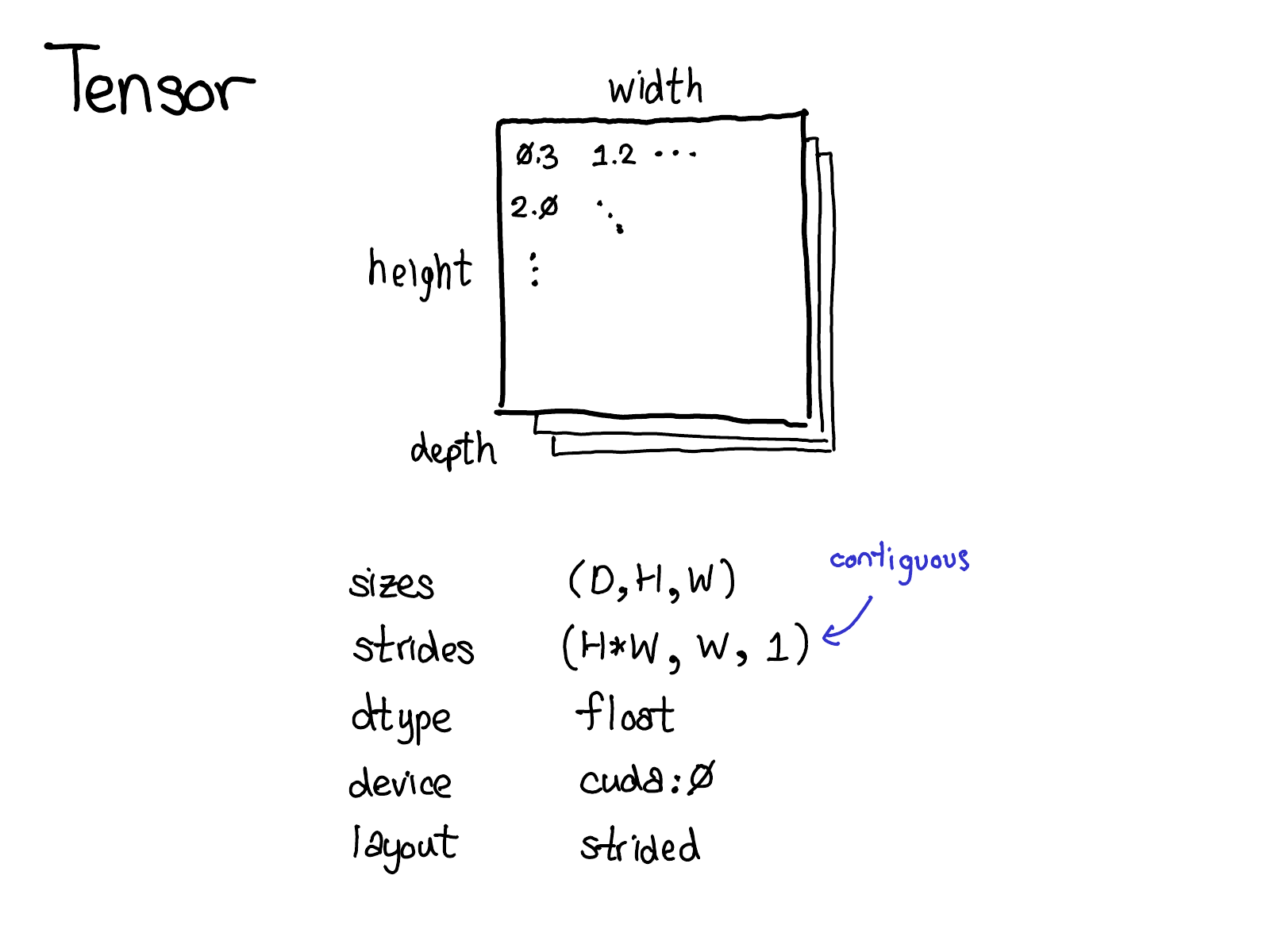
也有一些你可能不太熟悉的元数据:步长(the stride),步长实际上是PyTorch的一个亮点,所以值得花点时间好好讨论一下它。
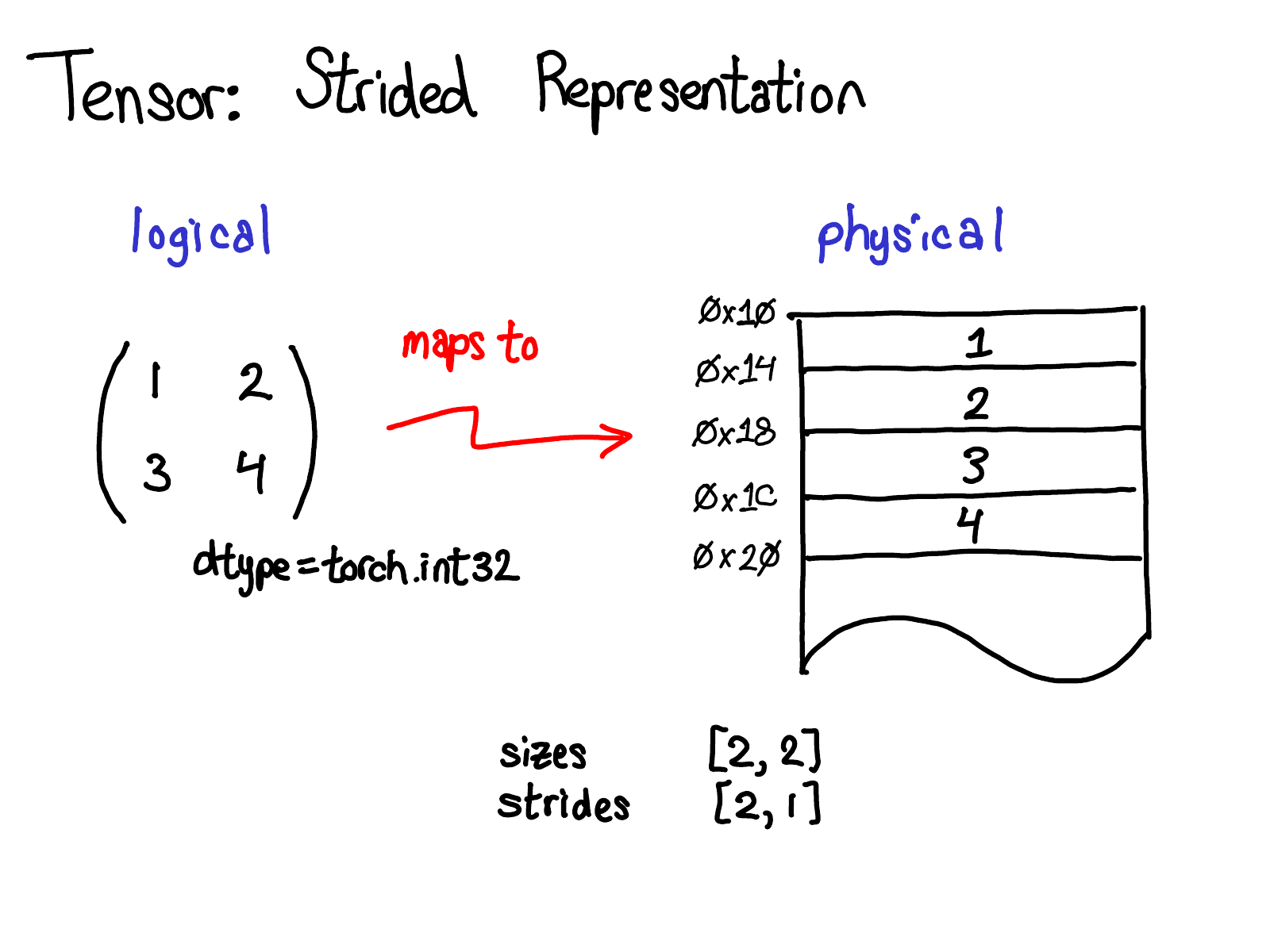
Tensor是一个数学概念。当用计算机表示数学概念的时候,通常我们需要定义一种物理存储方式。最常见的表示方式是将Tensor中的每个元素按照次序连续得在内存中铺开(这是术语contiguous的来历),将每一行写到相应内存位置里。如上图所示,假设tensor包含的是32位的整数,因此每个整数占据一块物理内存,每个整数的地址都和上下相邻整数相差4个字节。为了记住tensor的实际维度,我们需要将tensor的维度大小记录在额外的元数据中。
那么,步长在物理表示中的作用是什么呢?

假设我想要访问位于tensor [1, 0]位置处的元素,如何将这个逻辑地址转化到物理内存的地址上呢?步长就是用来解决这样的问题:当我们根据下标索引查找tensor中的任意元素时,将某维度的下标索引和对应的步长相乘,然后将所有维度乘积相加就可以了。在上图中我将第一维(行)标为蓝色,第二维(列)标为红色,因此你能够在计算中方便的观察下标和步长的对应关系。求和返回了一个0维的标量2,而内存中地址偏移量为2的位置正好储存了元素3。
(在后面的演讲中,我会讨论TensorAccessor,一个方便的类来处理下标到地址的计算。当你使用TensorAccessor而不是原始的指针的时候,这个类能隐藏底层细节,自动帮助你完成这样的计算)
步长是实现PyTorch视图(view)的根基。例如,假设我们想要提取上述tensor的第二行:
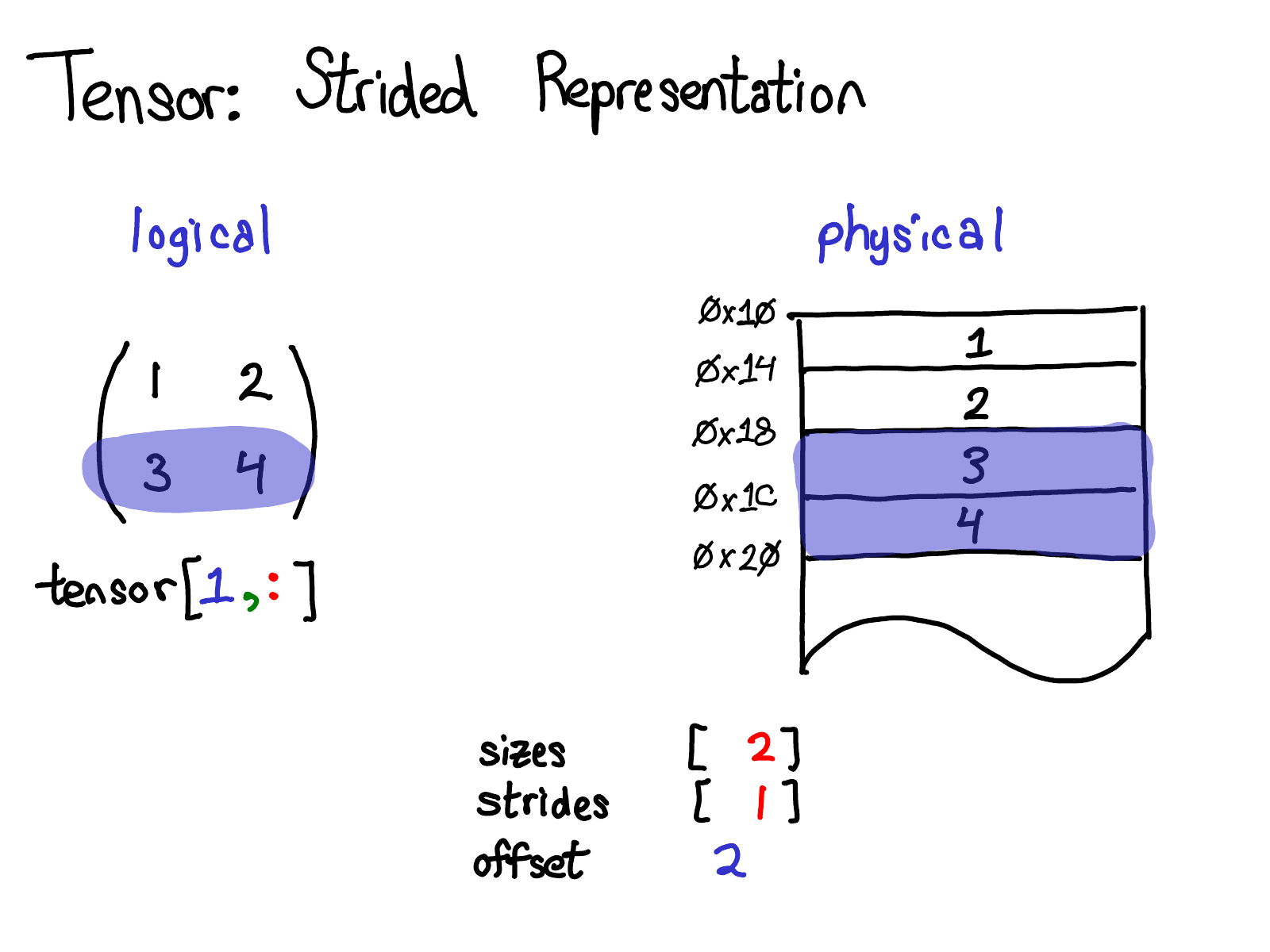
使用高级索引技巧,我只需要写成tensor[1, :] 来获取这一行。重要的事情是:这样做没有创建一个新的tensor;相反,它只返回了原tensor底层数据的另一个视图。这意味着如果我编辑了这个视图中的数据,变化也会反应到原tensor上。在这个例子中,不难看出视图是怎么做的:3和4存储在连续的内存中,我们所要做的是记录一个偏移量(offset),用来表示新的视图的数据开始于原tensor数据自顶向下的第二个。(每一个tensor都会记录一个偏移量,但是大多数时候他们都是0,我在图片中忽略了这样的例子)
来自于演讲的问题:如果我给一个tensor生成了一个视图,我怎样释放掉原tensor的内存?
回答:你必须要复制一份这个视图,以切断和原tensor物理内存的关系。除此之外,别无选择。顺便提一下,如果你之前写过Java,拿到一个字符串的子字符串有相似的问题,因为默认情况下不会产生数据的复制,因此子字符串关联着(可能非常大的)原字符串。这个问题在Java 7u6被修复了。
一个更有趣的例子是假设我想要拿第一列的数据:
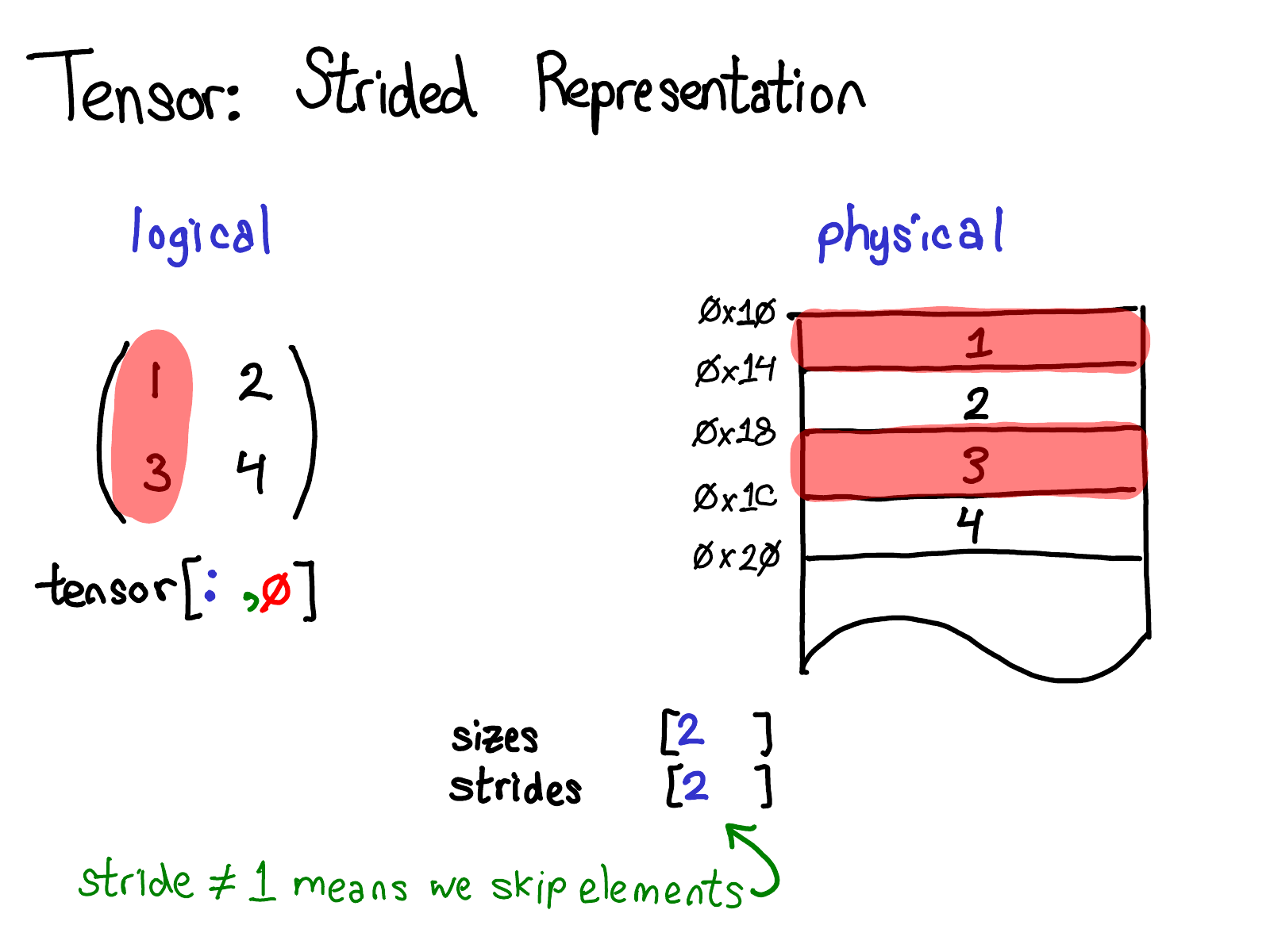
物理内存中处于第一列的元素是不连续的:每个元素之间都隔着一个元素。这里步长就有用武之地了:我们将步长指定为2,表示在当前元素和下一个你想访问的元素之间, 你需要跳跃2个元素(跳过1个元素)。
步长表示法能够表示所有tensor上有趣的视图,如果你想要进行一些尝试,见步长可视化。
让我们退一步想想如何实现这种机制(毕竟,这是一个关于内部机制的演讲)。要取得tensor上的视图,我们得对tensor的的逻辑概念和tensor底层的物理数据(称为存储 storage)进行解耦:
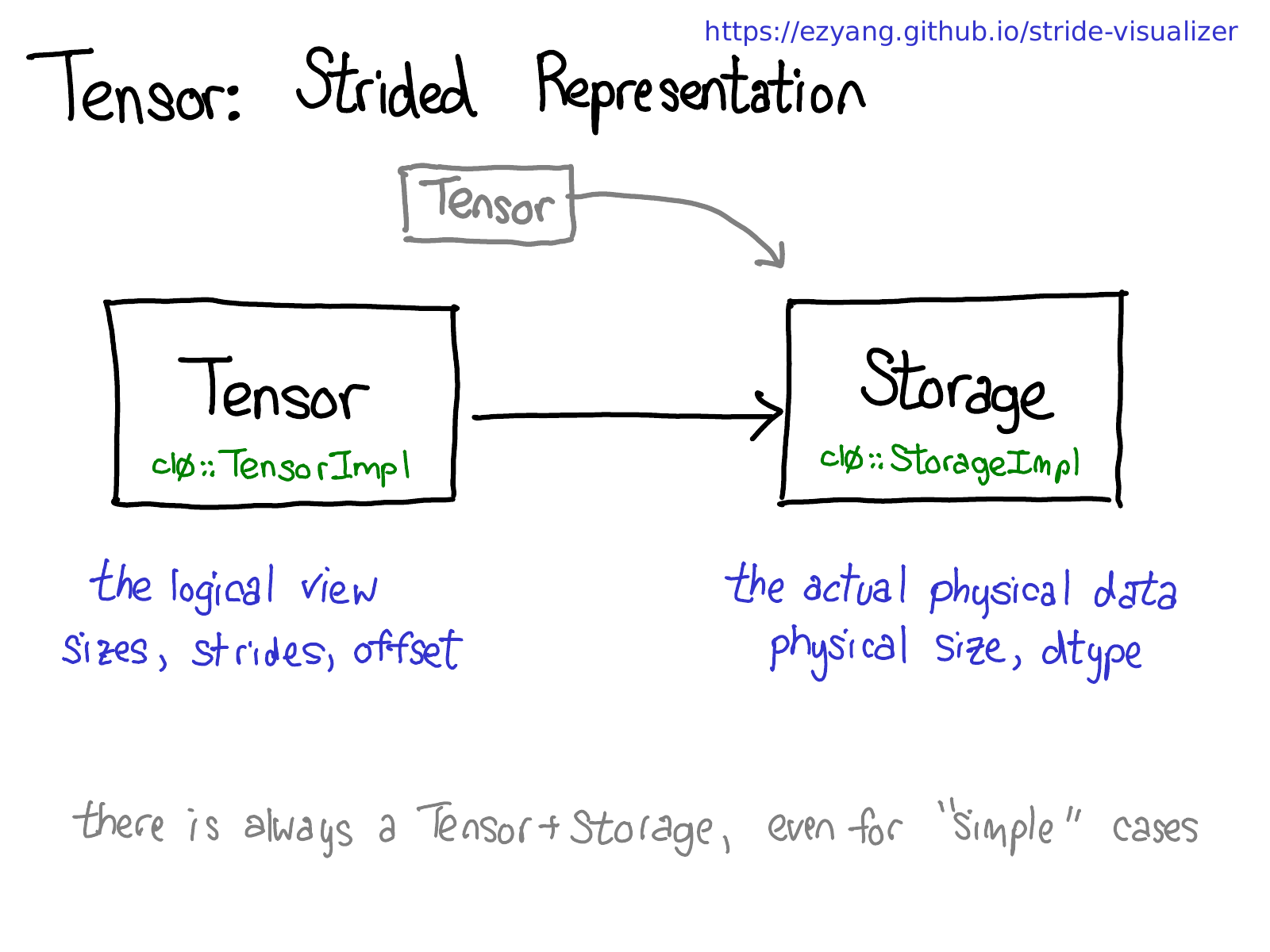
一个存储可能对应多个tensor。存储定义了tensor的数据类型和物理大小,而每个tensor记录了自己的大小(size),步长(stride)和偏移(offset),这些元素定义了该tensor如何对存储进行逻辑解释。
值得注意的是即使对于一些不需要用到存储的”简单”的情况(例如,通过torch.zeros(2,2)分配一个内存连续的tensor),总是存在着Tensor-Storage对。
顺便提一下,我们也对改进这样的模型很感兴趣。相比于有一个独立的存储,只基于现有tensor定义一个视图。这有一点点复杂,但是优点是可以更加直接的表示连续tensor,而不需要tensor到存储的转化。这样的变化将会使PyTorch的内部表示更加像Numpy。
我们对于tensor的数据布局(data layout)做了相当多的讨论,(有人会说,如果你能够将数据底层表示搞清楚,剩下的一切就顺理成章了)。但是我觉得还是有必要简要的探讨一下tensor上的操作(operations)是如何实现的。抽象来说,当你调用torch.mm的时候,会产生两种分派(dispatch):
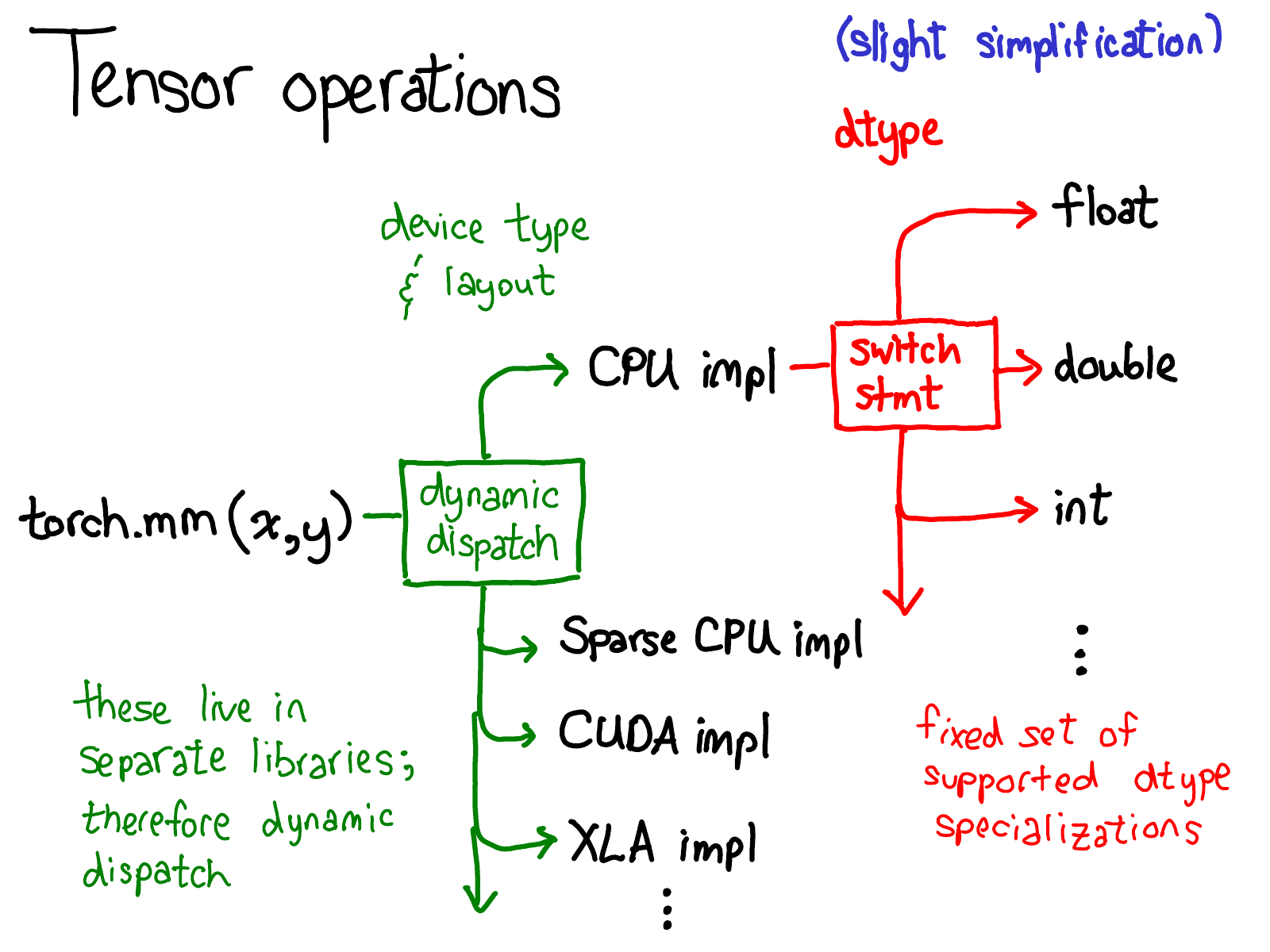
第一种分派基于设备类型(device type)和tensor的布局(layout of a tensor),例如这个tensor是CPU tensor还是CUDA tensor;或者,这个tensor是基于步长的(strided) tensor 还是稀疏tensor。这是一种动态分派的过程:使用一个虚函数调用实现(虚函数的细节将在教程的后半部分详述)。这种动态分派是必要的因为显然CPU和GPU实现矩阵乘法的方式不同。这种分派是动态的因为对应的kernels(理解为具体的实现代码)可能存在于不同的库中(e.g. libcaffe2.so 或 libcaffe2_gpu.so),如果你想要访问一个没有直接依赖的库,你就得动态的分派你的函数调用到这些库中。
第二种分派基于tensor的数据类型(dtype)。这种依赖可以通过简单的switch语句解决。稍稍思考,这种分派也是有必要的:CPU 代码(或者GPU代码)实现float类型矩阵乘法和int类型矩阵乘法也会有差异,因此每种数据类型(dtype)都需要不同的kernels。
如果你想要理解operators在PyTorch中是如何调用的,上面这张图也许最应该被记住。当讲解代码的时候我们会再回到这张图。
Layout/Device/Dtype

既然我们一直在讨论Tensor,我还想花点时间讨论下tensor扩展(extension)。毕竟,日常生活中遇到的tensor大部分都并不是稠密的浮点数tensor。很多有趣的扩展包括XLA tensors,quantized tensors,或者MKL-DNN tensors。作为一个tensor library我们需要考虑如何融合各种类型的tensors。
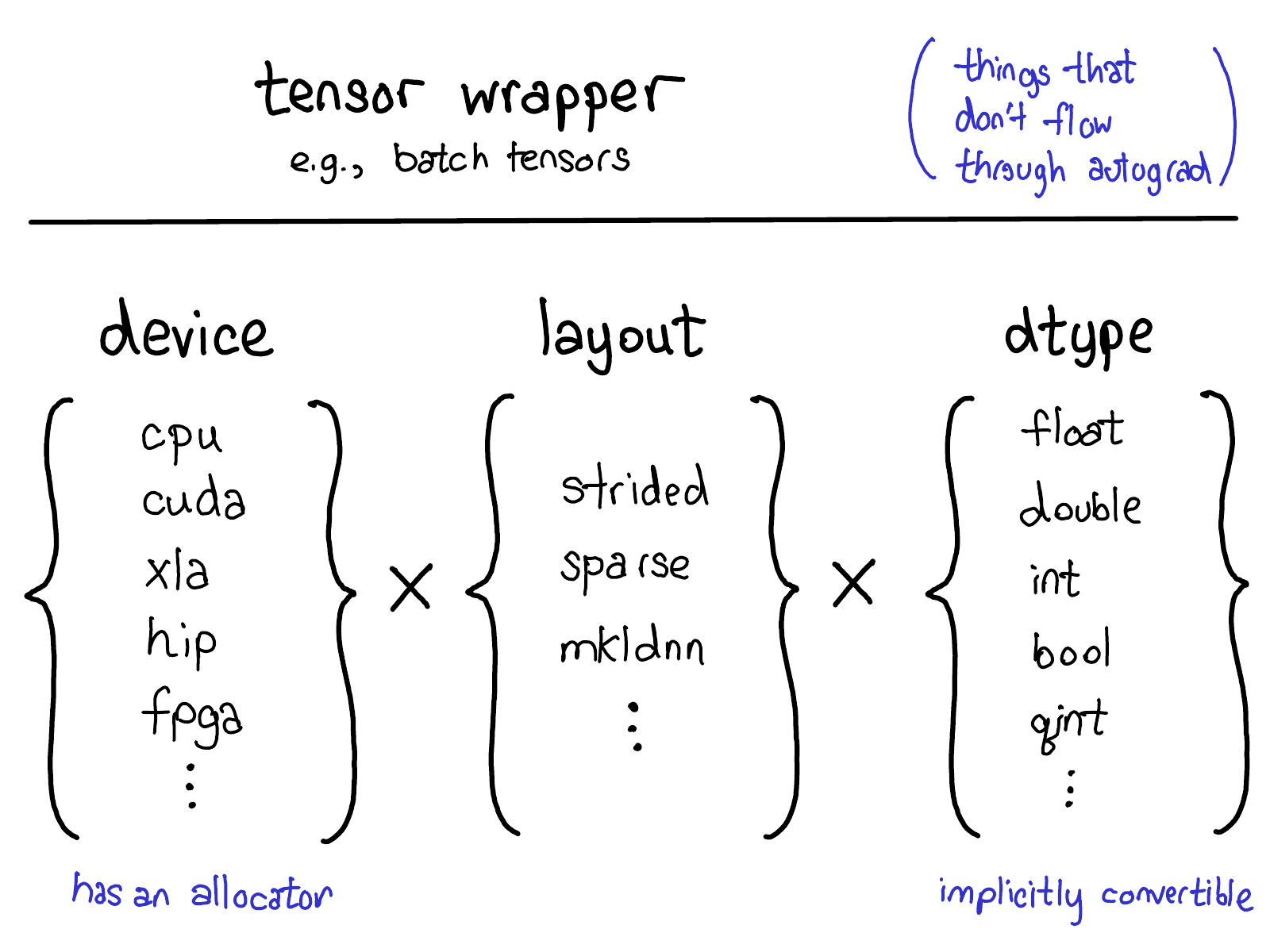
目前来说PyTorch的扩展模型提供了4种扩展方法。首先,能够唯一确定Tensor类型的”三要素”是:
- 设备类型(The device) 设备类型描述了tensor的到底存储在哪里,比如在CPU内存上还是在NVIDIA GPU显存上,在AMD GPU(hip)上还是在TPU(xla)上。不同设备的特征是它们有自己的存储分配器(allocator),不同设备的分配器不能混用。
- 内存布局(The layout) 描述了我们如何解释这些物理内存。常见的布局是基于步长的tensor(strided tensor)。稀疏tensor有不同的内存布局,通常包含一对tensors,一个用来存储索引,一个用来存储数据;MKL-DNN tensors 可能有更加不寻常的布局,比如块布局(blocked layout),这种布局难以被简单的步长(strides)表达。
- 数据类型(The dtype) 数据类型描述tensor中的每个元素如何被存储的,他们可能是浮点型或者整形,或者量子整形。
如何你想要增加一种PyTorch tensor类型(顺便说下,请联系我们如果你真的想要做这个!这个目前来说不是那么容易得事情),你应该想想你要扩展上面提到的哪一个决定张量类型的因素(“三要素”)。目前为止,并不是所有的组合都有对应的kernel(比如FPGA上稀疏量子张量的计算就没有现成的kernel),但是原则上来说大部分的组合都可能是道理的,因此至少在一定程度上我们支持它们。
还有一种方法可以用来扩展Tensor,即写一个tensor的wrapper类,实现你自己的对象类型(object type)。听起来很显然,但是很多人却在该用wrapper扩展的时候却选择了扩展上述三种要素。wrapper类扩展的一个非常好的优点是开发非常简单。
什么时候我们应该写一个tensor wrapper或者扩展PyTorch tensor?一个至关重要的测试是在反向自动求导的过程中你是否需要传递该tensor。例如通过这样的测试,我们就可以知道应该通过扩展PyTorch的方式实现稀疏tensor,而不是建立一个包含索引tensor和值tensor的Python对象(wrapper方式):因为当在一个包含Embedding的网络上做优化的时候,我们希望生成的梯度也是稀疏的。
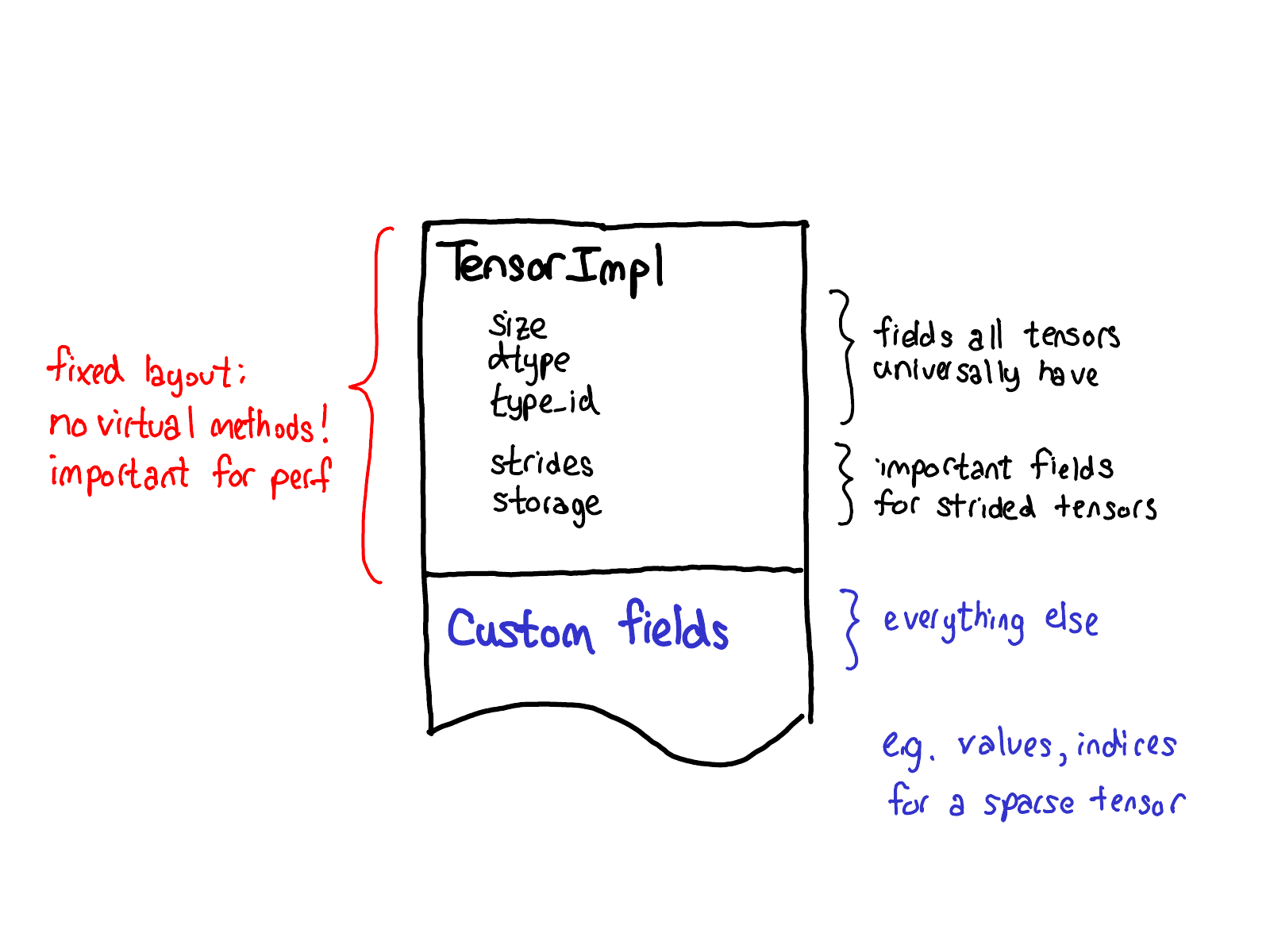
我们关于tensor扩展的哲学也对tensor自身的数据布局产生着一定的影响。我们始终希望tensor结构能有个固定的布局:我们不希望一些基础的operator(这些operator经常被调用),如size of tensor需要一个虚分派 (virtual dispatches)。因此当你观察Tensor实际的布局的时候(定义在 TensorImpl 结构体中),一些被我们认为是所有类型tensor都会有的字段定义在前面,随后跟着一些strided tensors特有的字段(我们也认为它们很重要),最后才是特定类型tensor的独有字段,比如稀疏tensor的索引和值。
Autograd
上面讲述的都是tensor相关的东西,不过如果Pytorch仅仅提供了Tensor,那么它不过是numpy的一个克隆。PyTorch 发布时一个区别性的特征是提供了自动微分机制(现在我们有了其他很酷的特性包括TorchScript;但是当时,自动微分是仅有的区别点)
自动微分到底做了什么呢?自动微分是训练神经网络的一种机制:
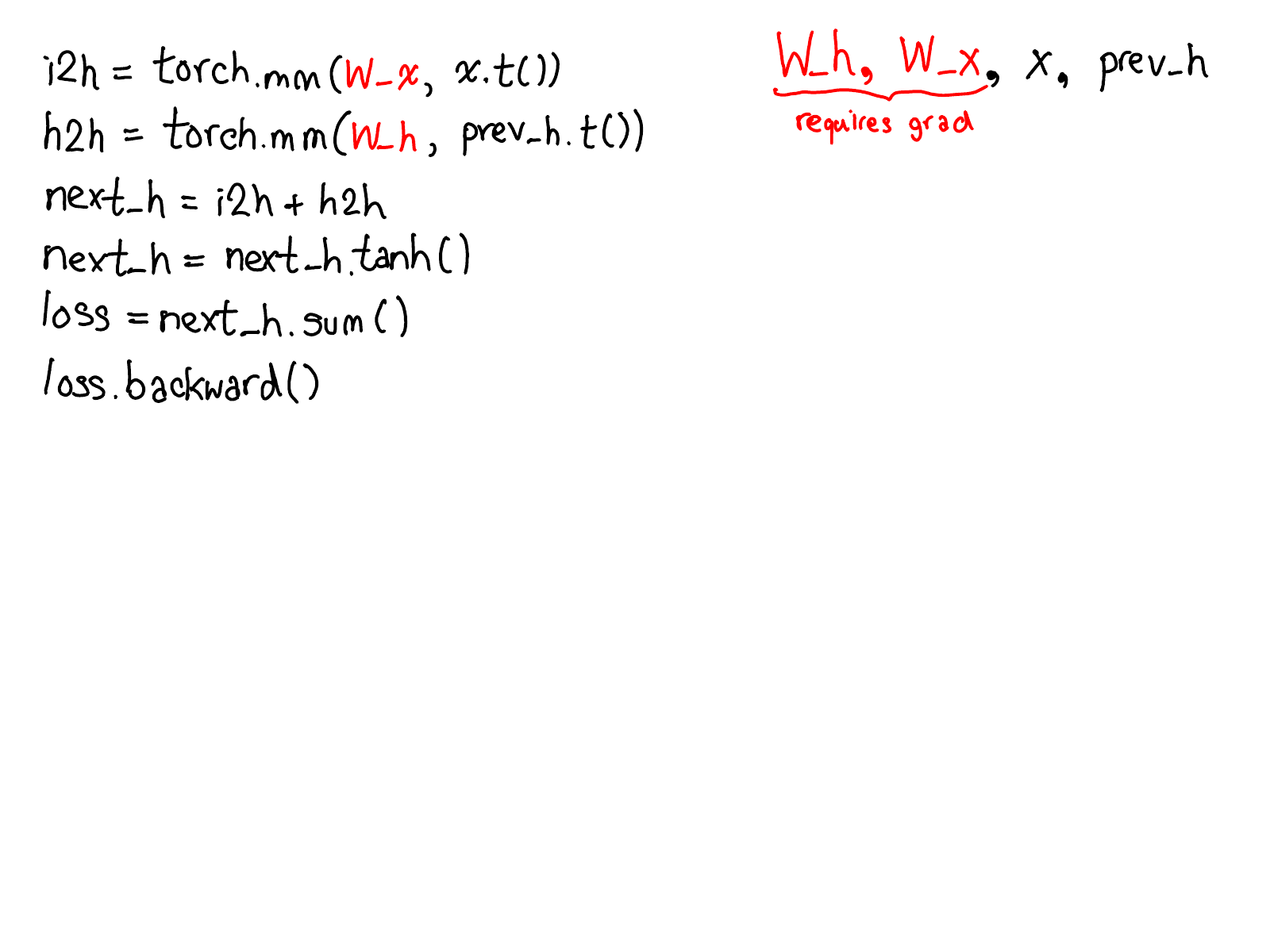
…下面这张图补充了计算loss的gradients所需要的代码:

请花一点时间学习上面这张图。有一些东西需要展开来讲;下面列出了哪些东西值得关注:
- 首先请忽略掉那些红色和蓝色的代码。PyTorch实现了reverse-mode automatic differentiation (反向模式自动微分),意味着我们通过反向遍历计算图的方式计算出梯度。注意看变量名:我们在红色代码区域的最下面计算了loss;然后,在蓝色代码区域首先我们计算了grad_loss。loss 由 next_h2计算而来,因此我们计算grad_next_h2。严格来讲,这些以grad_开头的变量其实并不是gradients;他们实际上是Jacobian矩阵左乘了一个向量,但是在PyTorch中我们就叫它们grad,大部分人都能理解其中的差异。
- 即使代码结构相同,代码的行为也是不同的:前向(forwards)的每一行被一个微分计算代替,表示对这个前向操作的求导。例如,
tanh操作符变成了tanh_backward操作符(如上图最左边的绿线所关联的两行所示)。前向和后向计算的输入和输出颠倒过来:如果前向操作生成了next_h2,那么后向操作取grad_next_h2作为输入。
概述之,自动微分做了下图所示的计算,不过实质上没有生成执行这些计算所需的代码。PyTorch 自动微分不会做代码到代码的转换工作(即使PyTorch JIT确实知道如何做符号微分(symbolic differentiation))。
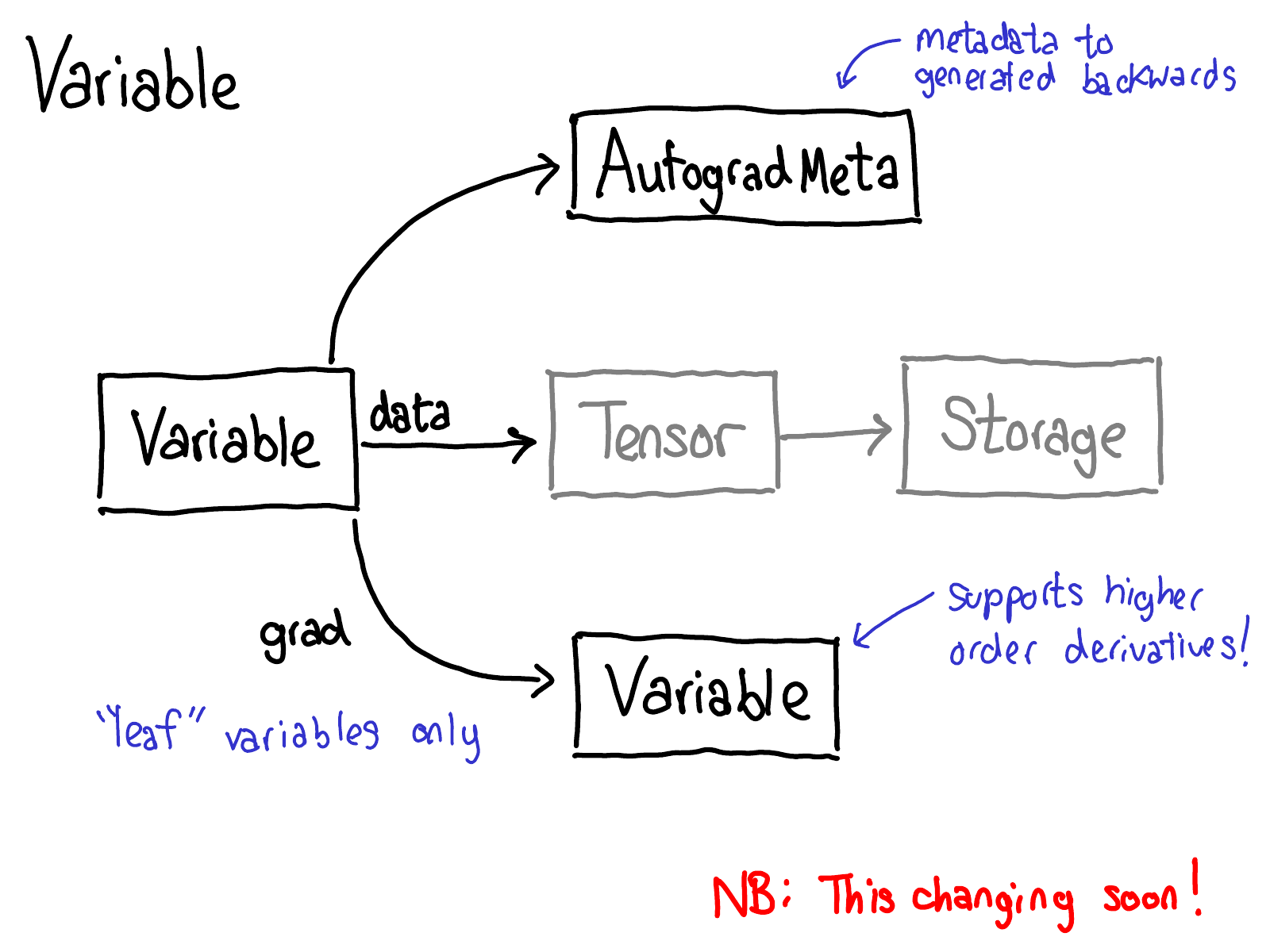
为了实现这个,当我们在tensor上调用各种operations的时候,一些元数据(metadata)也需要被记录下来。让我们调整一下tensor数据结构的示意图:现在不仅仅单单一个tensor指向storage,我们会有一个封装着这个tensor和更多信息(自动微分元信息(AutogradeMeta))的变量(variable)。这个变量所包含的信息是用户调用loss.backward()执行自动微分所必备的。
顺便我们也更新下分派的图:
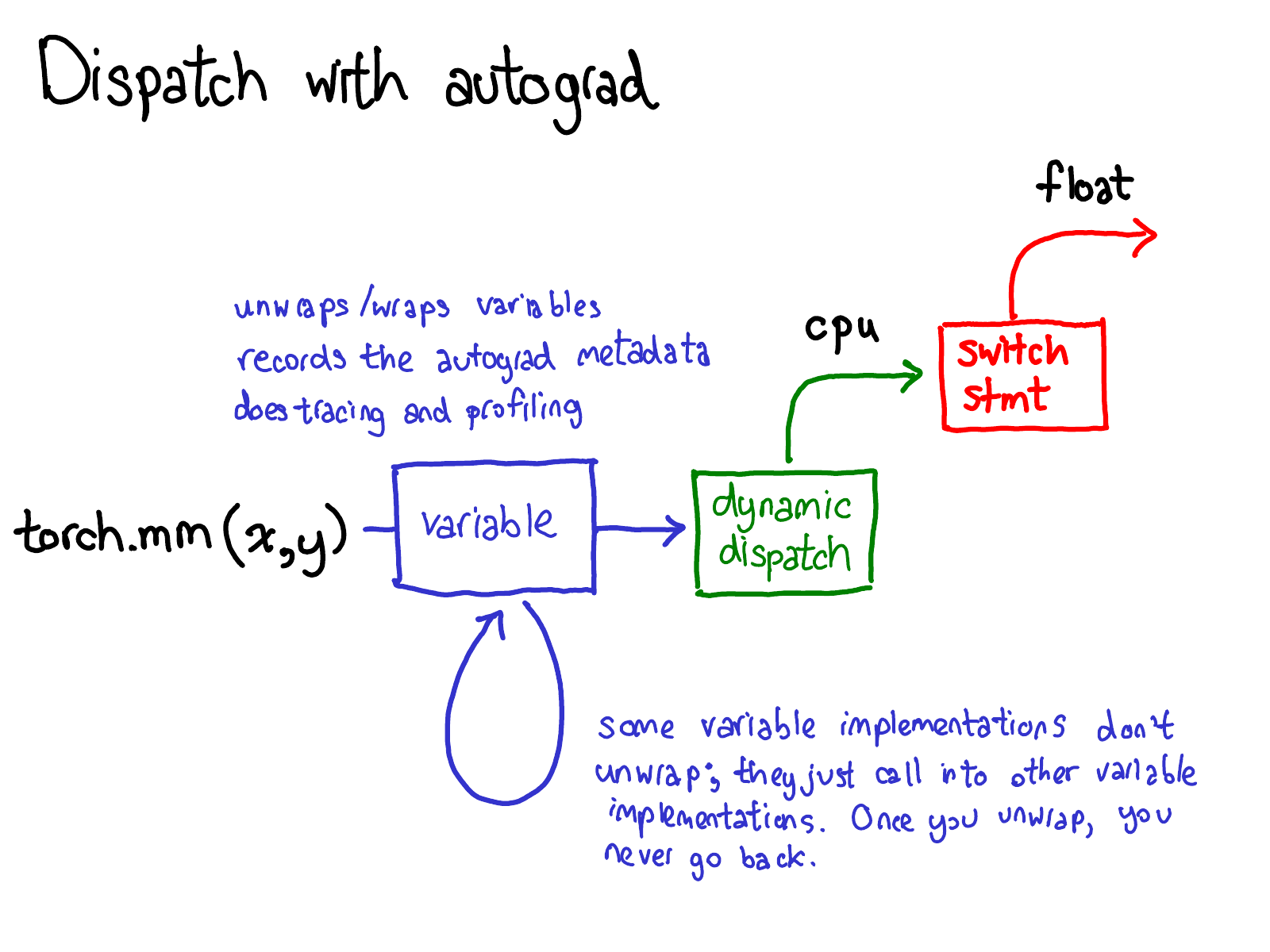
在将计算分派到CPU或者CUDA的具体实现之前,变量也要进行分派,这个分派的目的是取出变量内部封装的分派函数的具体实现(上图中绿色部分),然后再将结果封装到变量里并且为反向计算记录下必要的自动微分元信息。
当然也有其他的实现没有unwrap操作;他们仅仅调用其他的变量实现。你可能会花很多时间在变量的调用栈中跳转。然后,一旦某个变量unwrap并进入了非变量的tensor域,变量调用栈就结束了,你不会再回到变量域,除非函数调用结束并且返回。
Mechanics
到此我们已经讨论了足够的概念了,现在来看看具体的代码实现。

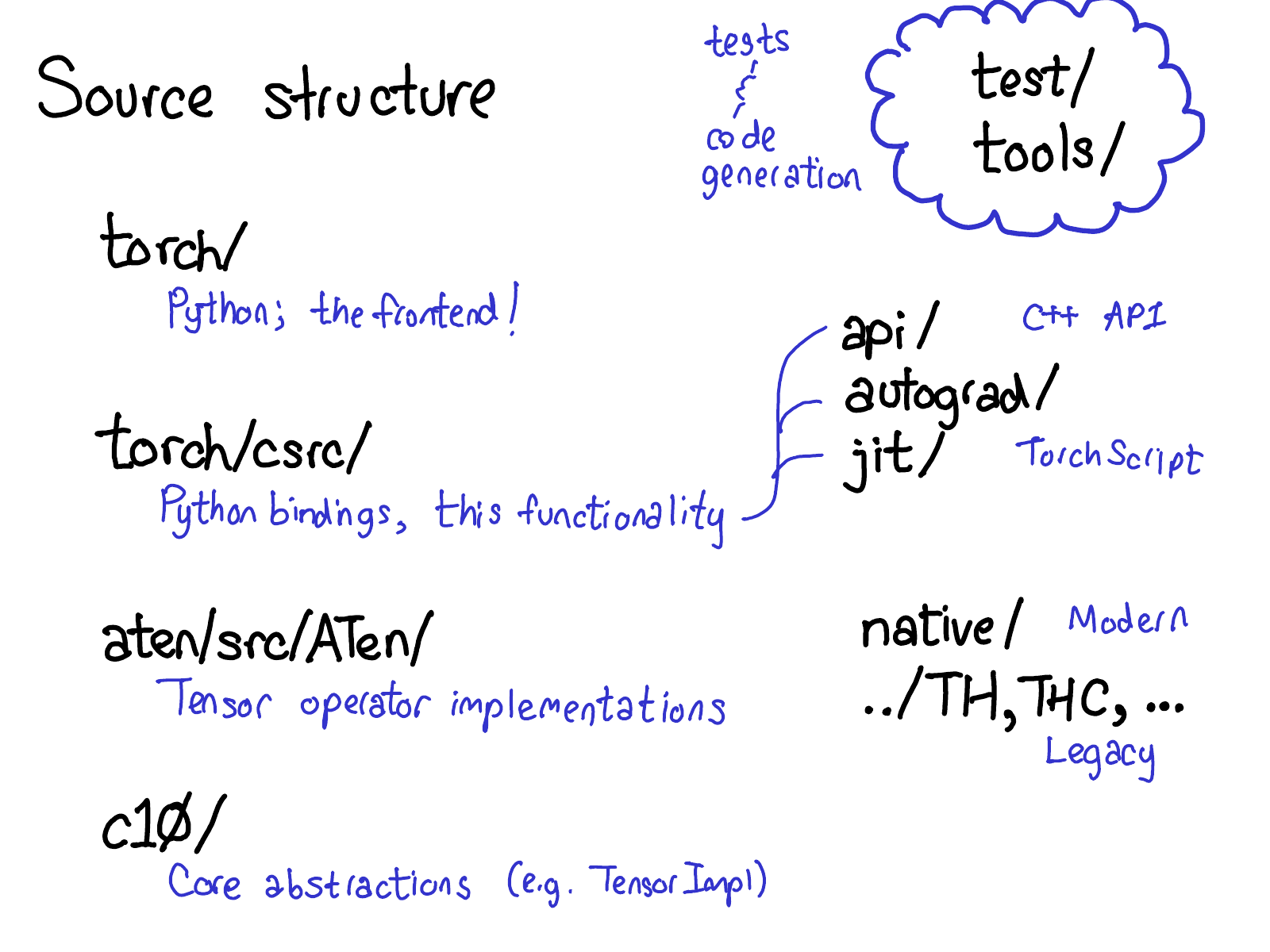
PyTorch的源码包含许多文件目录,CONTRIBUTING 文件里给这些目录做了详细的解释,不过实话说,你只需要关注4个目录:
- 首先,
torch/包含了你最熟悉的部分:你在代码中引入并使用的Python 模块(modules),这里都是Python代码,容易修改起来做各种小实验,然后,暗藏在这些表层代码的下面是: -
torch/csrc/,这部分C++代码实现了所谓的PyTorch前端(the frontend of PyTorch)。具体来说,这一部分主要桥接了Python逻辑的C++的实现,和一些PyTorch中非常重要的部分,比如自动微分引擎(autograd engine)和JIT编译器(JIT compiler)。 aten/,是”A Tensor Library”的缩写,是一个C++库实现了Tensor的各种operations。如果你需要查找一些实现kernels的代码,很大几率上他们在aten/文件夹里。ATen 内对operators的实现分成两类,一种是现代的C++实现版本,另一种是老旧的C实现版本,我们不提倡你花太多的时间在C实现的版本上。c10/,是一个来自于Caffe2 和 A”Ten“的双关语(Caffe 10),其中包含了PyTorch的核心抽象,Tensor和Storage数据结构的实际实现部分。
有如此多的地方看源码,我们也许应该精简一下目录结构,但目前就是这样。如果你做一些和operators相关的工作,你将花大部分时间在aten上。
Operator call stack
下面我们来看看实践中这些分离的代码分别用在那些地方:

(译注:下面这一部分需要对C++的机制有想当的了解,比如虚函数调用等等,我添加了一些自己的理解,尽力翻译得易懂一些,但是不保证完全正确,原文链接供参考)
当你调用一个函数比如torch.add的时候,会发生那些事情?如果你记得我们之前讨论过的分派机制,你的脑海中会浮现一个基本的流程:
- 我们将会从Python 代码转到 C++代码(通过解析Python调用的参数) (译注:解析调用参数下面代码中有例子)
- 处理变量分派(VariableType到Type),顺便说一下,这里的Type和程序语言类型没有关系,只是在分派中我们这么叫它) (译注:这一部分博文中没有讨论,下面作者也澄清了这是个疏忽,所以忽略就好了)
- 处理 设备类型/布局 分派(Type) (译注:这一部分讨论)
- 找到实际上的kernel,可能是一个现代的函数(modern native funciton),可能是一个老旧的函数(legacy TH funciton, TH 后面会解释) (译注:现代的函数指C++代码,老旧的多指C代码,后面有详细讨论。)
每一个步骤具体对应到一些代码。让我们剖析这一部分代码:

上面的C++代码展示了分派具体怎样实现的,我们以一个C实现的Python function为例子 (译注:即下面的THPVariable_add, 以TH开头的大都是C代码,后文会介绍),这种实现在Python代码中我们会通过类似这样语句调用:
torch._C.VariableFunctions.add.THPVariable_add。
要强调的是上面这段代码是自动生成的。你不会在GitHub repository中搜索到它们,因此你必须得从源码构建PyTorch才能查看到它们。另一个重要的事实是,你不需要深入地了解这段代码干了什么;简单的扫一遍代码并且对大概的思路有个了解就足够了。如上图,我用蓝色标注了一些最重要的部分:如你所见,PythonArgParser class 用来从Python (译注:Python add方法)的 args和kwargs中生成C++ parser对象,(译注:通过parser对象的parse方法可以得到一个r对象,r里封装了左操作数r.tensor(0),操作符r.scalar(1)和右操作数r.tensor(1),见上面的代码) 然后我们调用dispatch_add函数(上图红色所示),它释放了Python的全局解释器锁(global interpreter lock) 然后调用一个一般方法作用到C++ tensor self上(译注:self tensor是C++ Tensor类的对象,C++ Tensor类见下面这张图)。当这个方法返回时,我们重新将Tensor封装回Python object。
(到此为止,ppt上有个疏漏:我应该向你展示关于Variable dispatch的代码。目前还没修复这个部分。你可以想象奇妙的魔法发生后,我们到了…)

当我们调用C++ Tensor类的add方法时候,虚分派还未发生。然而,一个内联(inline)函数会在”Type”对象上调用一个虚函数(译注:Type对象指代码中的type()返回的对象,虚函数指add方法)。这个方法才是真正的虚函数(这就是为什么我之前说Type是一个媒介,作用是引出虚调用)。在这个例子里,这个虚函数调用被分派到TypeDefault的类的add实现上,原因是我们提供了一个add的实现,这种实现在任何一种设备类型上(包括CPU和CUDA)都一致(译注:所以叫TypeDefault);假如我们对不同的设备有具体的实现,可能会调用类似于CPUFloatType::add这样的函数,意味着虚函数add最后将实际的add操作分派到的CPU上浮点数相加的具体kernel代码上。
根据预期,这个PPT很快将会过时了,Roy Li正在做一些替代Type分派的工作,这些工作将会使PyTorch对于移动设备支持的更好。
值得一提的是,所有的代码,直到对于具体kernel的调用,都是自动生成的。
这里有点绕,所以一旦你对执行流程的大方向有一定的了解,我建议你直接跳到kernels的部分。
Tools for writing kernels

PyTorch为kernels编写者提供了许多实用的工具。在这一节里,我们将会简要了解他们之中的一部分。但是首先,一个kernel包含那些东西?

我们通常上认为一个kernel包含如下部分:
- 首先,我们为kernel写了一些元数据(metadata),这些元数据驱动了代码生成,让你不用写一行代码就可以在Python中调用kernel。
- 一旦你访问了kernel,意味着你经过了设备类型/布局类型的虚函数分派流程。首先你要写的一点是错误检测(error checking),以保证输入tensors有正确的维度。(错误检测非常重要!千万别跳过它们!)
- 然后,一般我们会给输出tensor分配空间,以将结果写入进去
- 接下来是编写合适的kernel。到这里,你应该做数据类型分派(第二种分派类型dtype),以跳转到一个为特定数据类型编写的kernel上。(通常你不用太早做这个,因为可能会产生一些重复的代码,比如说一些逻辑在任何case上都适用)
- 许多高效的kernel需要一定程度上的并行,因此你需要利用多核(multi-CPU)系统。(CUDA kernels 暗含着并行的逻辑,因为它的编程模型是建立在大量的并行体系上的)
- 最后,你需要访问数据并做希望做的计算!
在接下来的PPT里,我会带你了解PyTorch提供的一些工具帮助你实现上述步骤。

为了充分利用PyTorch带来的代码生成机制,你需要为operator写一个schema。这个schema需要给定你定义函数的签名(signature),并且控制是否我们生成Tensor方法(比如 t.add())以及命名空间函数(比如at::add())。你也需要在schema中指明当一个设备/布局的组合给定的时候,operator的哪一种实现需要被调用。具体格式细节查看README in native
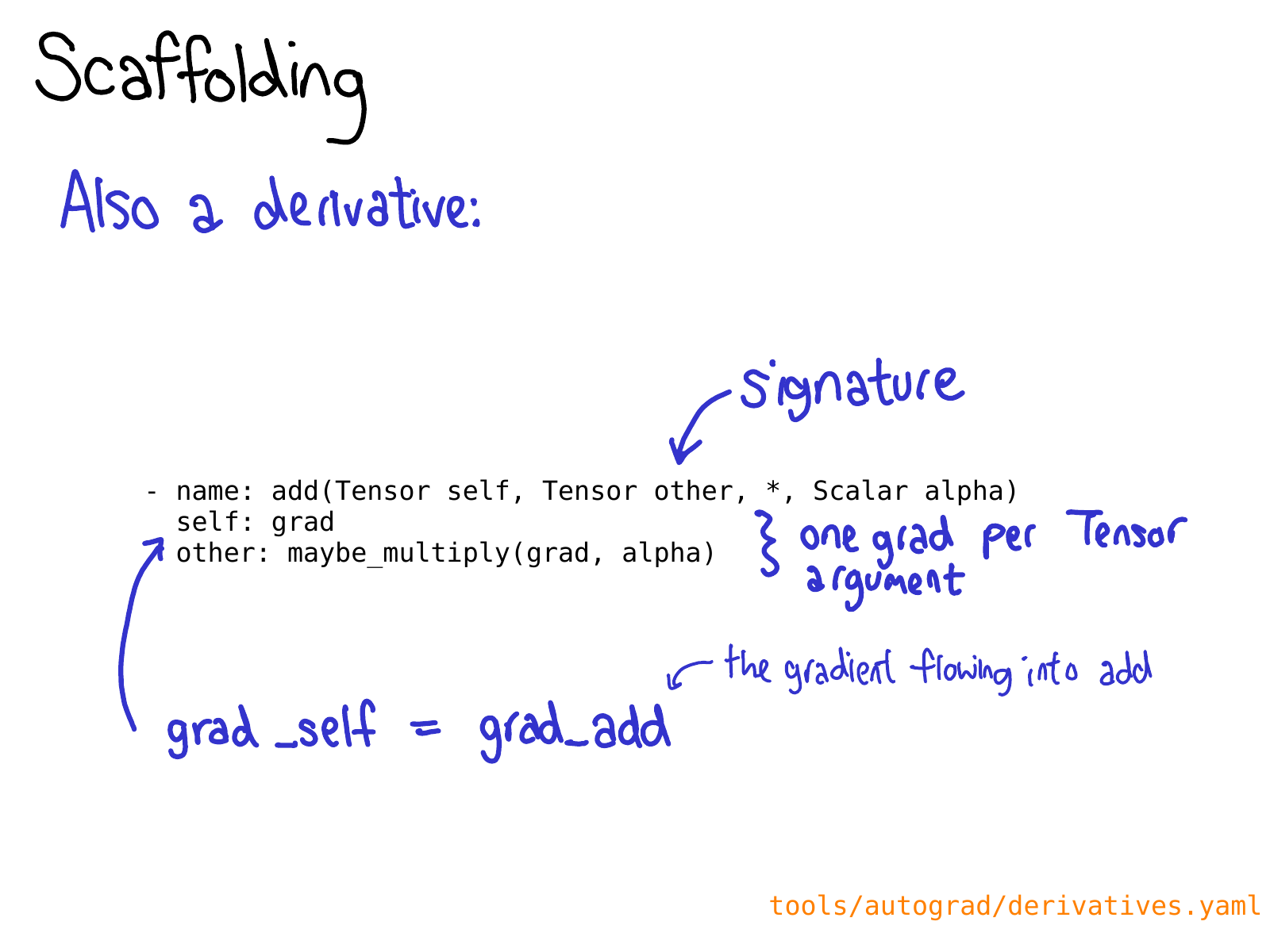
你也可能要在 derivatives.yaml 定义operation的求导操作。

错误检测既能通过底层API也能通过高层API来实现。底层API如宏(macro):TORCH_CHECK,输入一个boolean表达式,跟着一个字符串,如果根据Boolean表达式判断结果为false,这个宏就会输出字符串。这个宏比较好的地方是你能将字符串和非字符串数据混合起来输出,所有的变量都通过他们实现的«操作符格式化,PyTorch中大多数重要的数据类型都预定义了«操作符。(译注:这是C++中字符格式输出的方式,即通过重载«操作符)
高层API能够帮你避免写重复的错误提示。它的工作方式是首先你将每个Tensor封装进TensorArg中,TensorArg包含这个Tensor的来源信息(比如,通过它的参数名)。然后它提供了一系列封装好的函数来做各种属性的检测;比如,checkDim()用来检测是否tensor的维度是一个固定的数。如果它不是,这个函数会基于TensorArg中的元数据提供一个可读性好的错误提示。

Pytorch中编写operator的另一件值得注意的事情是,通常对一个operator,你需要编写三种版本:abs_out这个版本把输出存储在(out= 这个关键字参数中),abs_这个版本会就地修改输入,abs这个是常规版本(返回输出,输入不变)。
在大多数情况下,我们实现的是abs_out版本,然后通过封装的方式实现abs和abs_,但是也有给每个函数实现一个单独版本的时候。

为了做数据类型分派(dtype dispatch),你应当使用AT_DISPATCH_ALL_TYPES宏。这个宏的输入参数是Tensor的type,和一个可以分派各种的type类型的lambda表达式,通常情况下,这个lambda表达式会调用一个模板帮助函数(templated helper function,译注:也是C++中的概念,C++泛型会讨论到模板函数)。
这个宏不仅”做分派工作”,它也决定了你的kernel将会支持哪些数据类型。严格来说,这个宏有几个不同的版本,这些版本可以让你选择处理哪些特定的dtype子集。大多数情况下,你会使用AT_DISPATCH_ALL_TYPES,但是一定要留心当你只想要分派到特定类型的场景。关于在特定场景如何选择宏详见Dispatch.h

在CPU上, 你经常想要并行化你的代码。在之前,OpenMP 原语(pragmas) 经常被用来做并行化的工作。

在我们需要访问数据的时候,PyTorch提供了不少选择。
- 如果你仅仅想拿到存储在特定位置的数值,你应该使用
TensorAccessor。tensor accessor类似于tensor,但是它将维度(dimensionality)和数据类型(dtype)硬编码(hard codes)成了模板参数(template parameters 译注:代码里的x.accessor<float, 3> 表示数据类型是float, 维度是3)。当你通过x.accessor<float, 3>()得到一个accessor实例,PyTorch 会做一个运行时检测(runtime test)来保证tensor确实是这样的形式(format,译注:形式指数据类型和维度),但是在那之后,每一次访问都不会再检查。Tensor accessors能够正确的处理步长(stride),因此当你做些原始指针(raw pointer)访问的时候你应当尽量用它们 (不幸的是,一些老旧的代码并没有这样)。PyTorch里还有一个PackedTensorAccessor类,被用来在CUDA加载过程中传输accessor,因此你能够在CUDA kernel 内访问accessors。(小提示:TensorAccessor默认是64-bit索引的,在CUDA中要比32-bit索引要慢很多) - 如果你编写的operator需要做一些规律性的数据访问,比如,点乘操作,强烈建议你用高层API比如
TensorIterator。这个帮助类自动帮你处理了广播(broadcasting)和类型提升(type promotion),非常方便。(译注:广播和类型提升可以参考numpy相关的描述) - 为了在CPU上执行得尽量快,也许你需要使用向量化的CPU指令(vectorized CPU instructions)来编写kernel。我们也提供了工具!
Vec256类表示一个向量,并提供了一系列的方法以对其向量化的操作(vectorized operations)。帮助函数比如binary_kernel_vec让你更加容易得运行向量化的操作,以处理原始的CPU指令不容易处理的向量化的场景。同时,这个类还负责针对不同的指令集编译不同的kernel,然后在运行时对你CPU所支持的指令集做测试,以使用最合适的kernel。
Legacy code

PyTorch 中的许多kernel仍然由古老的TH类型的代码实现(顺便说一下,TH代表TorcH。缩写固然很好,但是太常见了,如果你看到了TH,就把它当做老旧的就好了)。下面详细解释下什么是老旧的TH类型:
- 它由C代码编写,没有(或者极少)用到C++
- 它是由手动引用计数的(当不再使用某个tensor的时候,通过手工调用
THTensor_free方法来减少引用计数) - 它存在于
generic/文件夹中,意味着我们需要通过定义不同的#define scalar_t来多次编译。
这些代码是很”疯狂”的,我们也不愿意维护它们,所以请不要再向里面添加东西了。你可以做的更有意义的事情是,如果你喜欢编程但是不熟悉关于kernel的编写,你可以尝试着移植这些TH函数到ATen里面去。
Workflow efficiency

作为总结,我想要讨论一些关于高效扩展PyTorch的技巧。如果说庞大的PyTorch C++代码库是第一道阻止很多人贡献代码到PyTorch的门槛,那么工作效率就是第二道门槛。如果你试着用写Python的习惯编写C++代码,你将会话花费大量的时间,因为重新编译PyTorch太耗时了,你需要无尽的时间来验证你的改动是否奏效。
如何高效得改动PyTorch可能需要另一场专门的talk,但是这个PPT总结了一些常见的”误区”:
- 如果你编辑了一个头文件,尤其是那种包含许多源文件(尤其是包含了CUDA文件),那么你可能会需要一个非常长时间的重新编译。为了避免这个,尽量保持只修改cpp文件,尽量少修改头文件!
- 我们的CI(译注:应该指一个云端的已配置好的环境,见链接)是一个非常好的,不需要任何配置的环境来测试你的修改是否会奏效。但是在你得到结果之前估计需要1到2小时。如果你的修改需要大量的实验验证,把时间花在设置一个本地开发环境上吧。同样,如果你遇到了一个特别难以debug的问题,在本地环境中测试它。你可以下载并且使用我们的Docker镜像 download and run the Docker images locally
- 如何贡献的文档详述了如何设置
ccache,我们强烈推荐这个,因为很多情况下它会在你修改头文件时帮助你节省重新编译的时间。它也能帮助你避免一些我们编译系统的bugs,比如重新编译了一些不该重新编译的文件。 - 我们有大量的C++代码,推荐你在一个有着充足CPU和RAM资源的服务器上编译。强烈不建议你用自己的笔记本编译CUDA,编译CUDA是特特特特别慢的,笔记本不具备快速编译的能力。
Conclusions
总之这份教程带你快速扫过PyTorch内部机制!许多东西没有被讨论到,但是希望以上的描述和解释能够帮助你对代码的大体结构有个初步的了解。
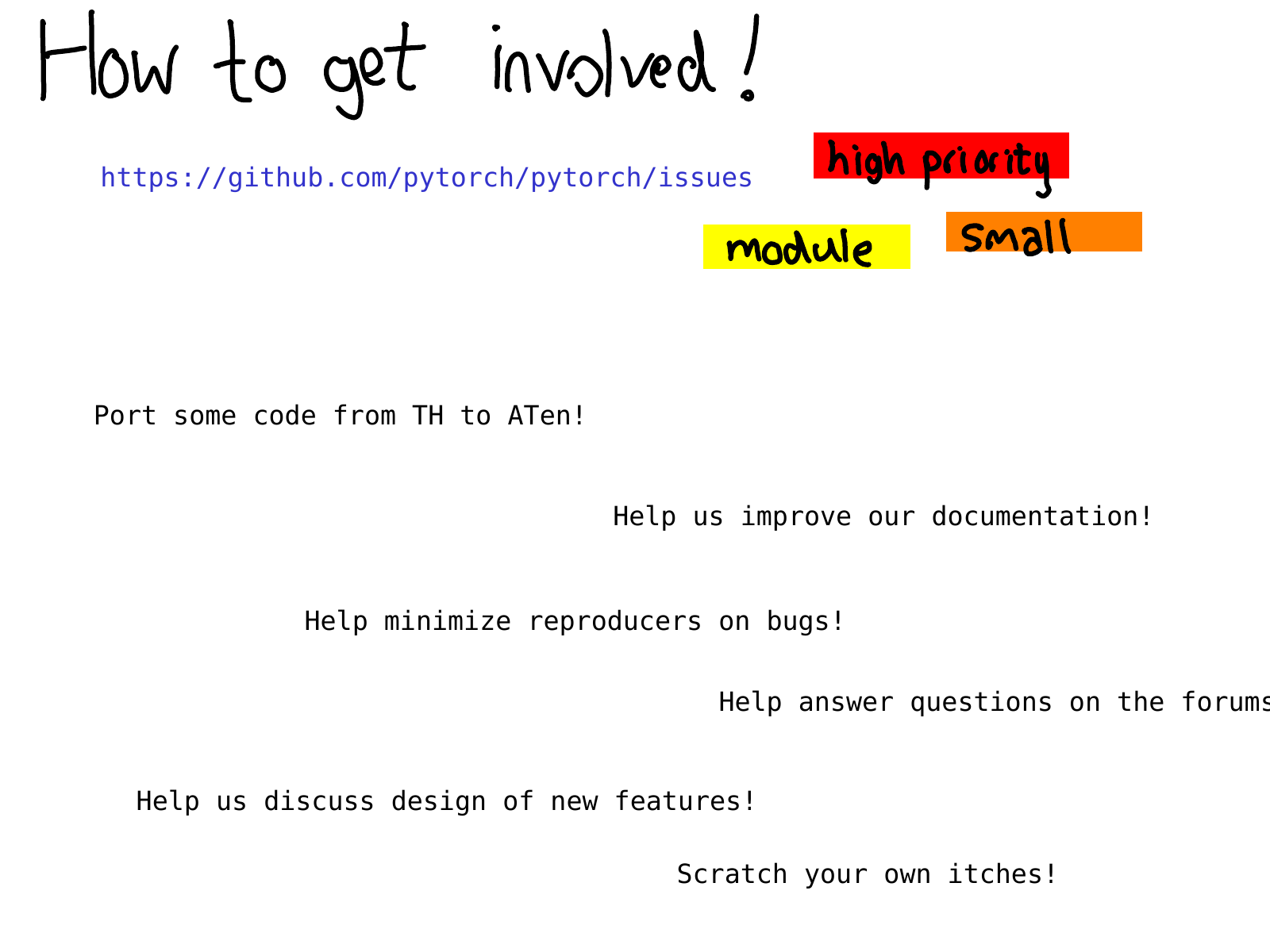
看完这份教程后你需要去哪里获得更详细的资源?你能够做哪种类型的贡献?一个比较好的起点是我们的问题追踪器(issue tracker)。在今年早些时候,我们开始对问题进行标注,一个标注过的问题意味着至少有一个PyTorch开发者注意到了它并且做了初始的任务评估。通过这些标注你能够知道我们认为哪些问题是high priority的,或者你可以查询属于特定模块的问题,例如 autograd ,或者你可以查询一些我们认为不是那么重要的小问题(警告:我们有时也会判断失误)
即使你不想立刻开始编程,也有很多有意义的工作比如改善文档(我喜欢合并文档的pull请求,它们实在是太好了),帮助我们复现其他用户报告的bug,帮助我们讨论问题追踪中的RFCs(request for comment,请求给出详细注释)。没有开源贡献者就没有PyTorch的今天,希望你们能加入我们!